


Biodiversity in an age of big data
Biodiversity in an age of big data
By Leo Ohyama
A significant portion of my current work delves into global-scale research questions which often involve large amounts of data from multiple sources. I’m still amazed by the volume and accessibility of data that I’ve witnessed and used for my work. I never thought that with just a few clicks of the mouse one can access tens of thousands of observational or museum records of different groups of organisms. You can also easily find and download dozens of global maps for climate conditions, habitat types, net primary productivity, tree density and many other abiotic variables. The sheer amount of biodiversity information can at times feel overwhelming, but funny enough, it’s only the tip of the iceberg. According to a recent study, ~10-20% of an estimated 1-2 billion specimens have been documented and curated by one of the largest biodiversity data portals, GBIF (Global Biodiversity Information Facility)1. This volume of data continues to increase and the rate of this increase gets faster every year (Figure 1).
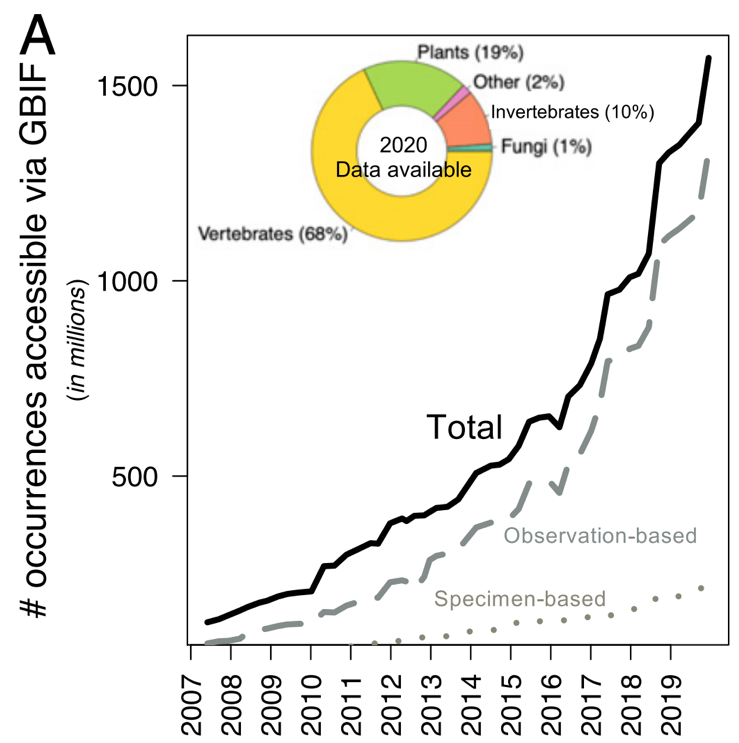
Biodiversity research that is driven by big data has reached new heights with many studies providing much needed insight for policymakers and conservation management. For example, a recent study was able to use 22 billion data points to identify biodiversity hotspots in international waters which have become targets for major human industries (oil drilling, fisheries etc.) and are less regulated given its independence from any national jurisdiction 2. Keep in mind these international waters are areas of our ocean that are mostly unexplored and lie beyond 370 kilometers of any physical coastline claimed by a sovereign nation.
The continued push to expand biodiversity data and further studies in this age of big data has provided a variety of research opportunities not only for scientists, but also the public in general. There are more opportunities for synthesis as different datasets coming from different scales are made available. The combination and integration of these different datasets to pursue larger and more encompassing research objectives also encourages collaborations across research institutions. The general public also play a significant role in the development of these databases as they have been able to collect, share, and access this data through applications such as iNaturalist. Data in this form made up 65% of occurrence data in GBIF in 2020 compared to 7% in 20071.
While I’m enthusiastic and excited for the future of biodiversity research driven by big data, I am not without caution. Most of this caution comes from two main concerns. The first is the taxonomic integrity of these data and the second being the ability of scientists to work with these data.
Data literacy
One of the most important components to studying biodiversity is having robust taxonomical units. We need to be sure that species’ taxonomies are up to date and reflected in these large databases. Sometimes species are moved between genera or several species may be reclassified as one species (lots of lumping and splitting). To address these issues, there are programs and management systems, like Catalogue of Life, which are set up to document these changes for integration into big datasets such as GBIF. From my experience, these are not always reliable and the scientific names of the species observation data are often not up to date. There can always be conflicts such as whether we consider a subspecies as its own taxonomical unit. Luckily, I have collaborators who are trained taxonomists and who have helped me resolve these issues. To me, these issues really galvanize the need to support taxonomy and taxonomists, especially now when everything is becoming digitized. There is a frightening thought that in this exciting rush to go big with data that we forget what our data actually represent. Ultimately, we need to maintain vigilance and seek better solutions for maintaining taxonomic integrity especially considering the increasing volumes of data that we will continue to work with.
My journey to learning how to access, download, clean and integrate multiple data sets that come in a variety of different formats took many years and was mostly self-taught. These data literacy skills are essential when working with vast amounts of data and the tools and techniques for working with big data are continuously changing to meet demands. Fortunately, there are resources and programs that push for data skills development such as Data Carpentry. However, there needs to be improvements regarding the accessibility of this training. This is further outlined in Luis Montalvo’s excellent post on the digital divide in biodiversity research.
To me, the more exciting aspects of big data-driven biodiversity research is the movement to digitize and curate “dark data” (data that was previously inaccessible) 1,3, the continued push across multiple facets of biology to continue cataloguing biodiversity, and the potential advances in knowledge that can be synthesized from this data. The integration of “dark” data to the already growing databases will increase the resolution and accuracy of the lenses we use to evaluate and understand biodiversity. Furthermore, there are multiple initiatives to catalogue biodiversity that go beyond species observations such as the Earth BioGenome Project which aims to sequence the DNA of ~1.5 million species of eukaryotes. Finally, as an ecologist a lot of my interests lie in seeking generality and I’m sure other scientists from various fields share similar goals. This age of big data and the opportunities for synthesis that arise will, I hope, lead to progress in seeking generality in biodiversity.
Follow Leo on Twitter.
Check out blogs from other UFBI Fellows.